Ordinary Least Squares Compute Time
Scikit-learn’s linear_model.LinearRegression() documentation lists:
From the implementation point of view, this is just plain Ordinary Least Squares (scipy.linalg.lstsq) wrapped as a predictor object.
Why might scikit-learn’s implementation seem much faster than calling linalg.lstsq() on its own?
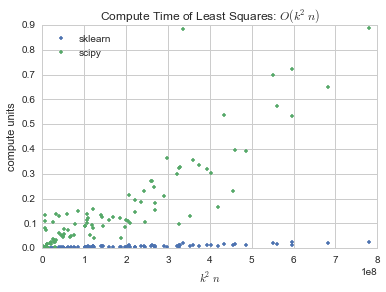
It appears scikit will cache results to precalculate features that haven’t changed. If you use random data instead with numpy.random.random_integers():
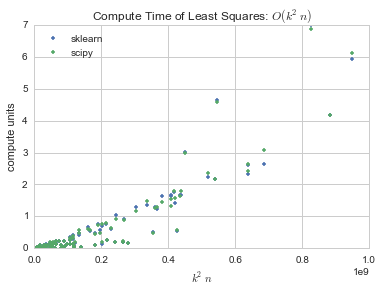
The results are more comparable.